How to write enterprise code!

So last year, I was at an internship, and as part of a project, I was tasked with making a new page on a webapp that just collected data from a few APIs and displayed it. Simple, right? Sure was. But what I quickly discovered was that the codebase was a maze of abstractions and dependencies that took quite some effort to decipher. Today, I want to walk through the "enterprise-ification" process good simple code, and how and why it turned into that abstraction labryinth. I'm going to start at the simplest solution and work my way up. Are these the best ways of solving these problems? Probably not for you- the right solution for any software problem depends on your specific requirements. But this is one way that it was solved in real enterprise code, and I think it's interesting to take a look at.
In the beginning, there was a simple requirement. Make a page that displays data from multiple APIs. Easy, here's how I would design that for a personal project.
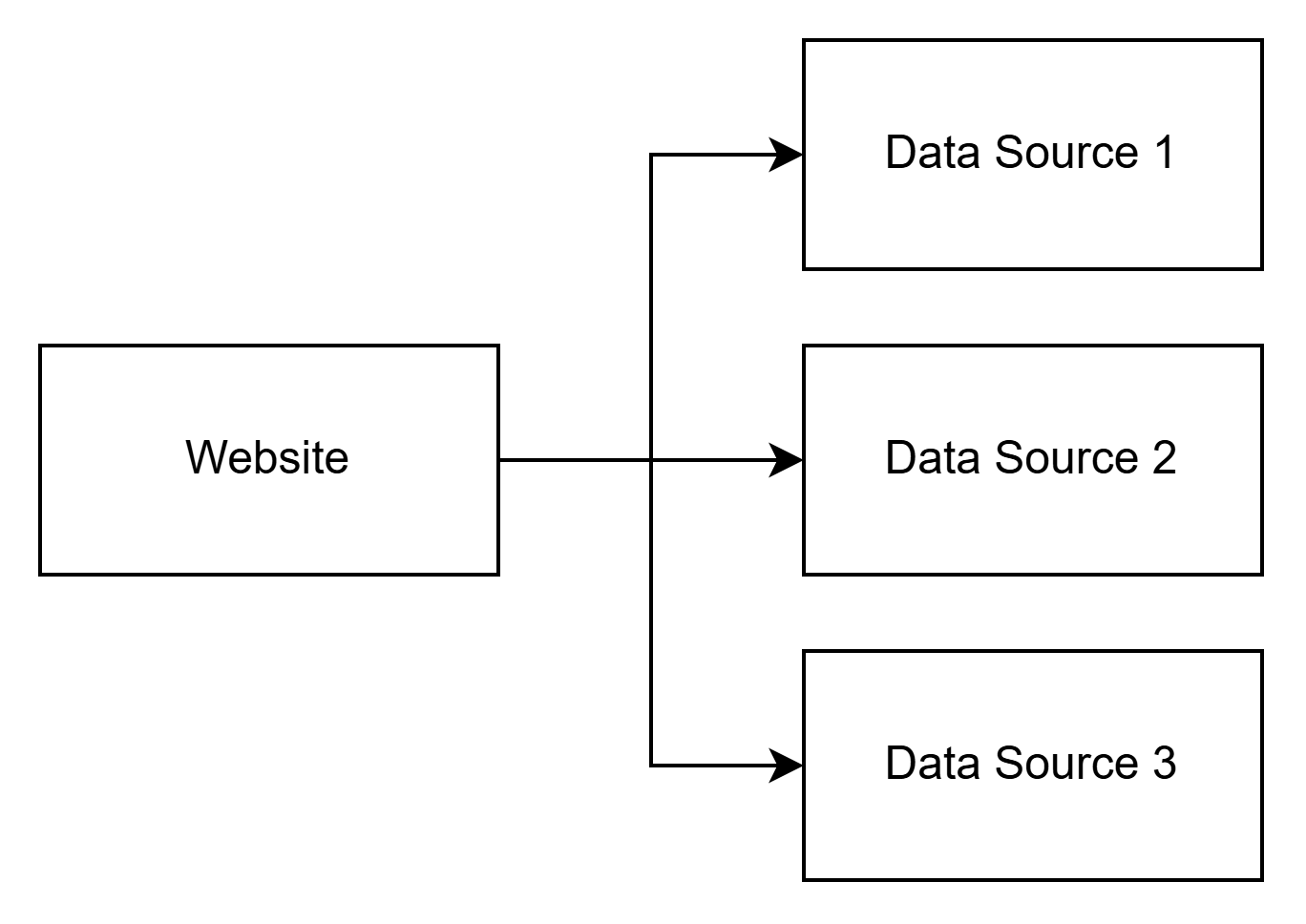
The website simply accesses each API and displays the information.
Ah, but now, a complication. The data sources are actually internal tools and services, and they shouldn't be accessible from the public internet for security reasons. So, what do we do? We build a backend service that will be responsible for accepting data requests from the internet and forwarding them to the internal tools to minimize the attack surface. Alright, sounds reasonable, let's build it out.
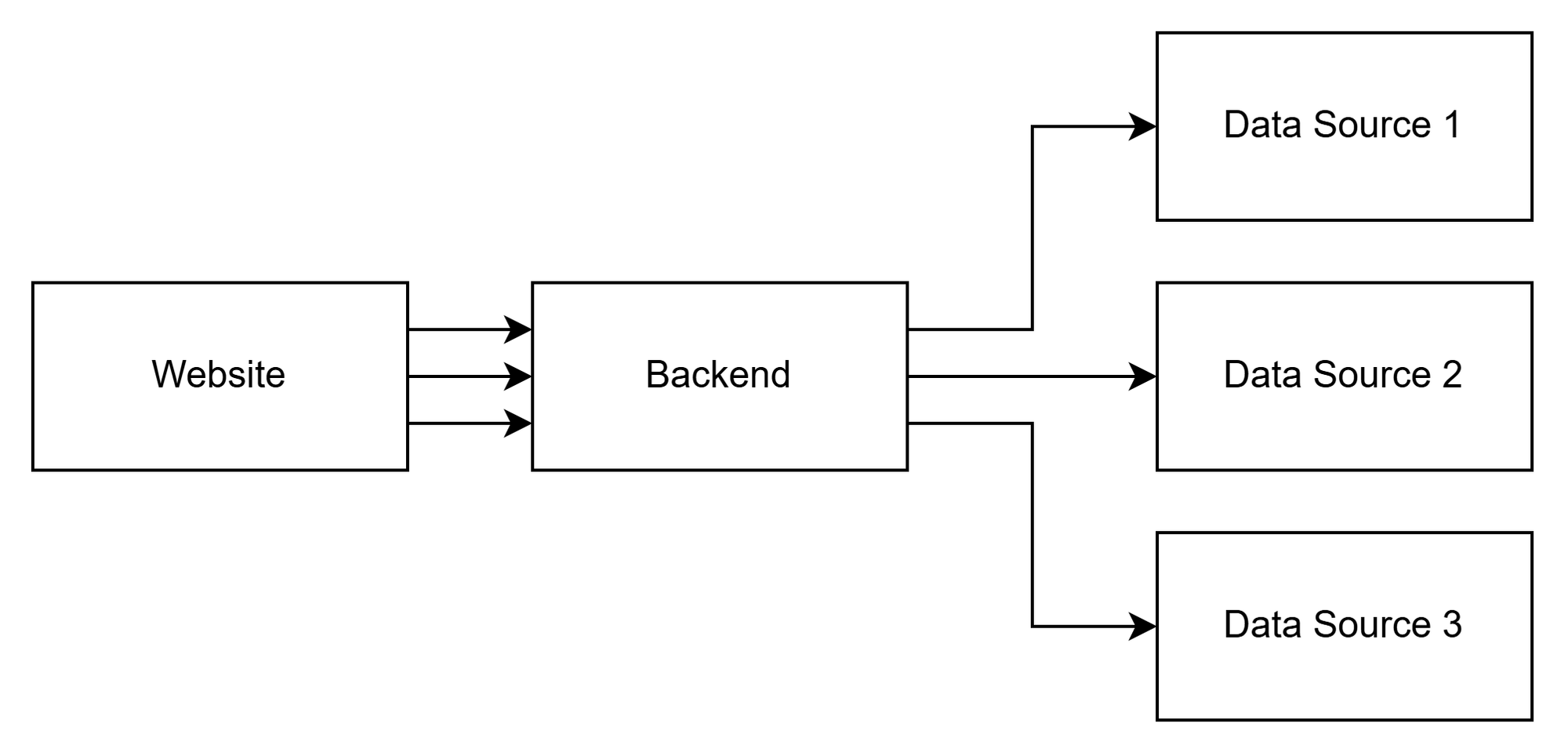
Our first bit of technical messiness appears. Now we have three API endpoints that just mirror other API endpoints. They have similar names, return essentially the same data, and make the code a bit more confusing to read. Is this getMetadata call going to the backend or the data source? You have to know the context of your code to know. The API endpoints still have to remain separate because fetching from the data source is an expensive operation (in my case) and I only want to fetch the data that the user requests.
Our next problem is that our system is not guaranteed to be robust. "Robust" might be a bit of a vague word, but in my case, it meant that if you made changes to the API producer or consumer, the system could break because the services have no way of knowing what the API schema is. Right now, you'd just be hoping that no one else touches the API to add new information. Okay, how do we solve this? Well, we can use a shared data model to enforce the type and shape of our API. Since each of the data sources is owned and developed by a separate team, they each get their own data model so they have control over their API. Sounds great, let's implement it.
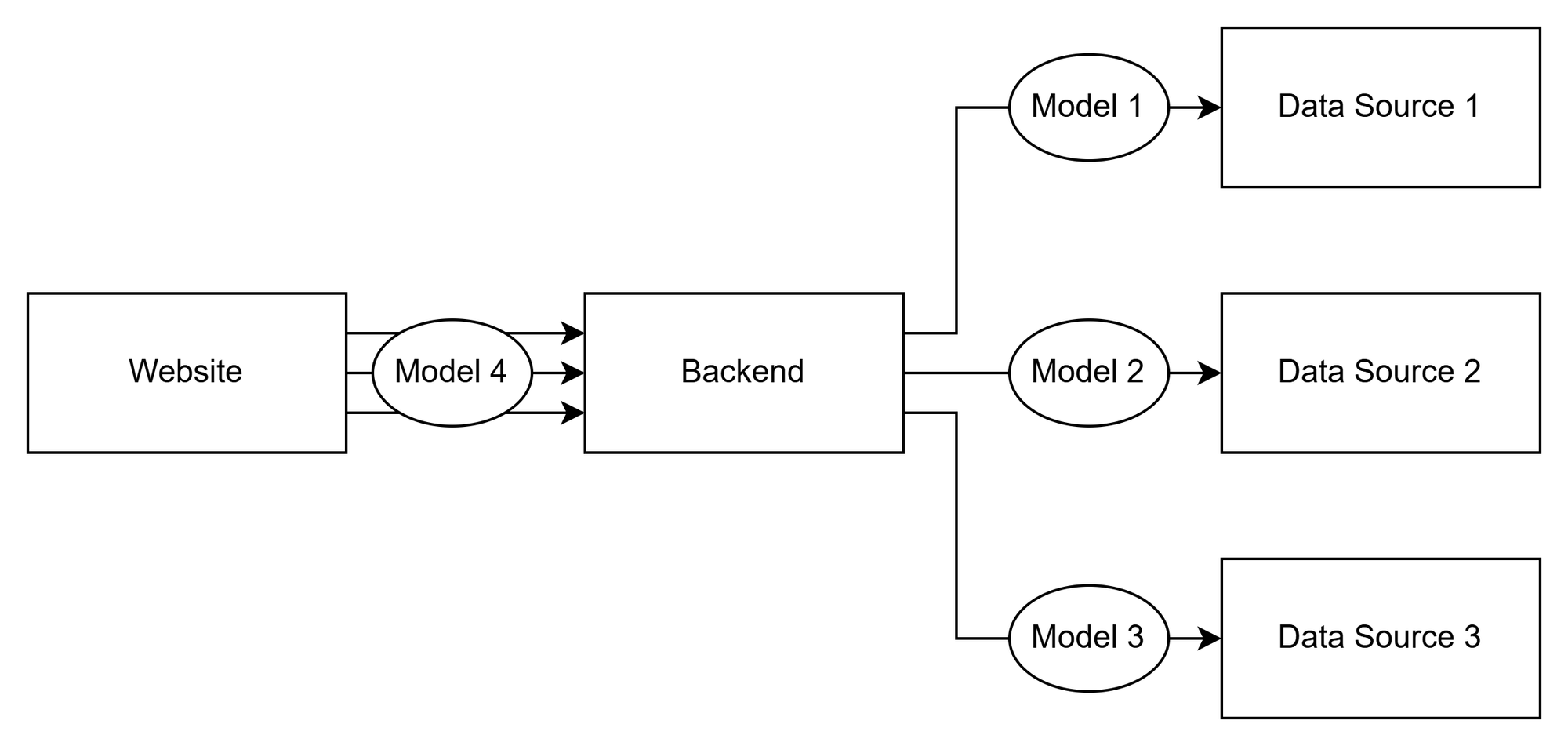
Great, now we have a data model that defines the API. But it's not enforced in any way. How do we do that? You can use a system that will automatically generate the API client for you. This way, as the data consumer, you'll always be parsing data correctly following the data model as a contract. To help show this, I'm going to make the diagram a little more detailed and show you the internals of the website and backend.
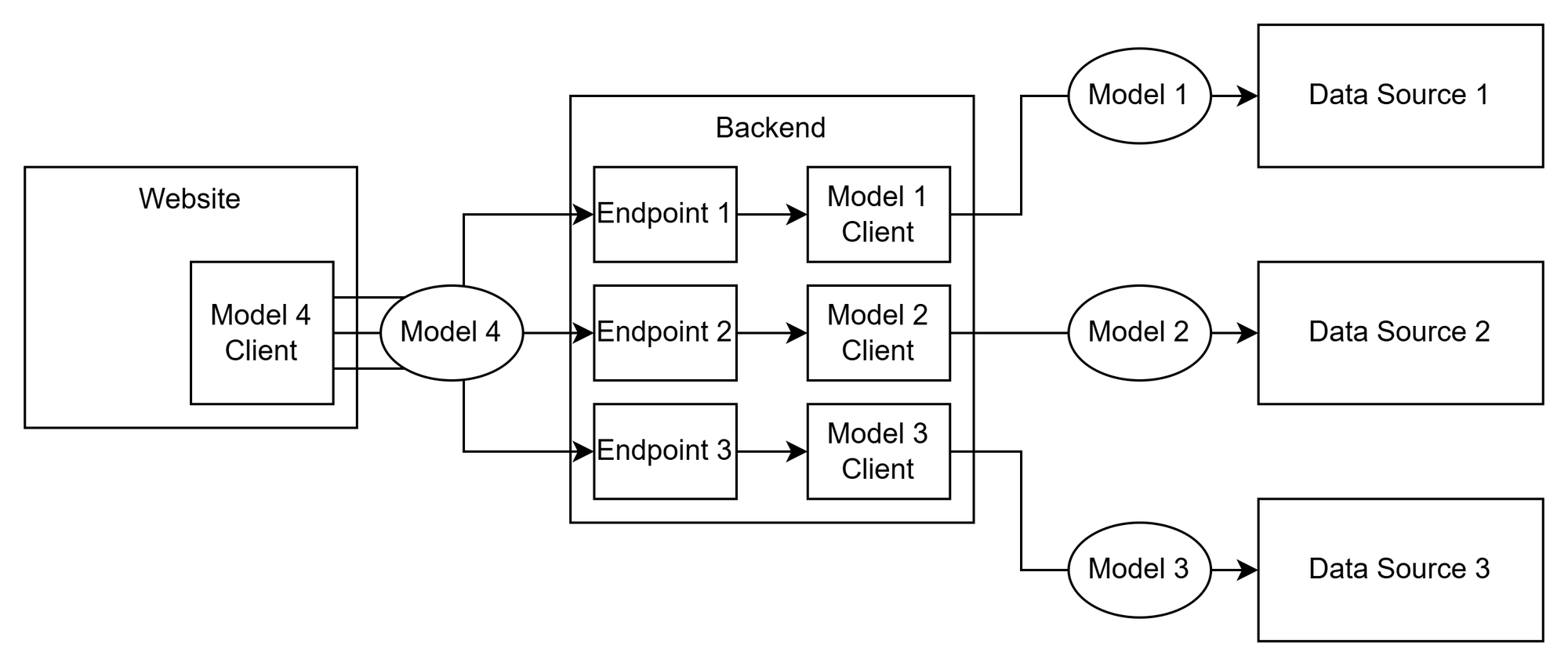
Now we have a frontend website that has an autogenerated API client that accesses the backend, which has multiple endpoints that each call the respective API client of the data source that they are accessing. But we're not quite done yet. As we are in object oriented programming land, the data returned by the APIs are stored as a typed object of a certain class while we're processing it. These classes are part of the autogenerated API client code. So that means that when we fetch the data from data source 1, it will be an object of the type Model1Response. But to send it to the website, it needs to be an object of the type Model4Response! Since the backend needs to comply with the data shape defined by the model, we need an adapter to change the type of the data, even though both types basically define the same information.
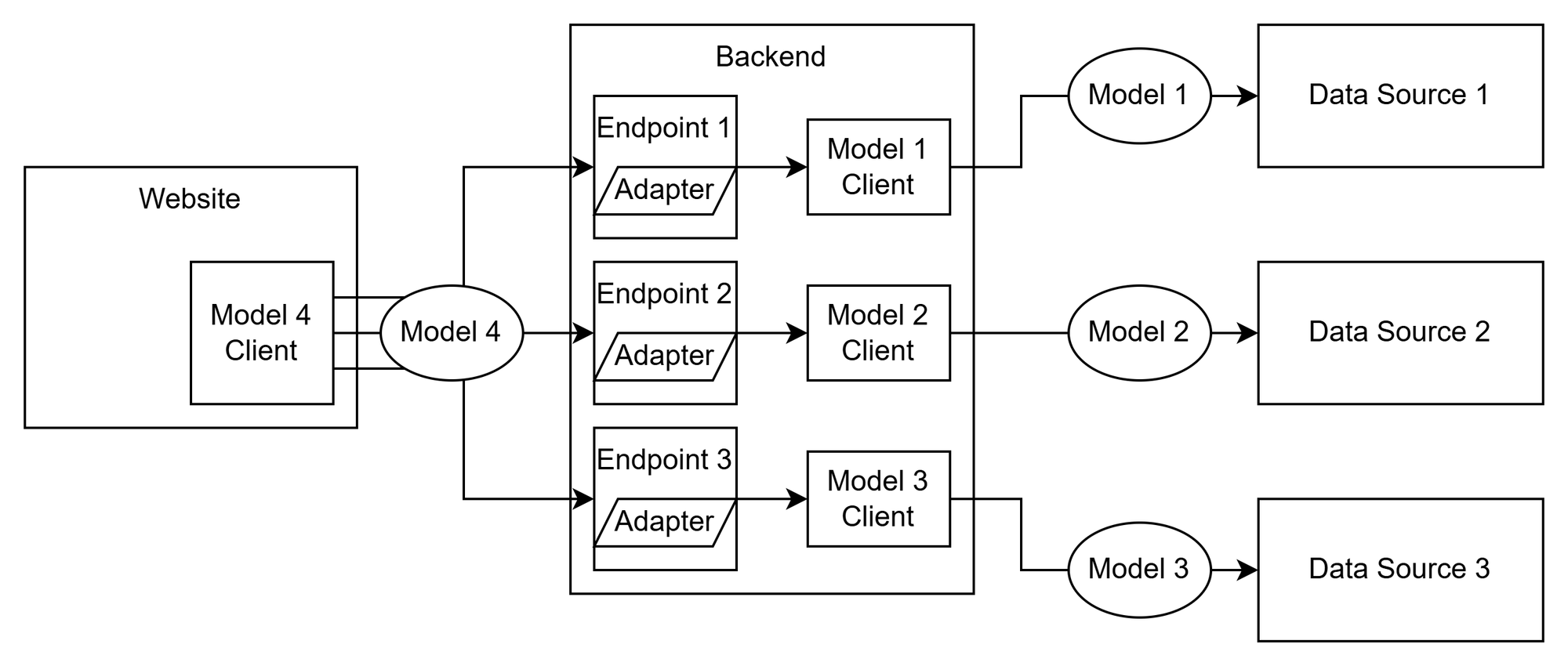
Phew! We've finally implemented our shared data model. You may be seeing the abstraction layer cake starting to appear.
We've written a lot of code, but no tests. To follow required code best practices (mandatory) we should write tests for our backend. Does it matter that all that the backend does is convert data from one data type to another? Nope. The code coverage number must go up!
When we're testing though, we don't want to actually call the data sources, that would make our tests nondeterministic and create an unneeded dependency that makes our tests less reliable. Instead, we should have a mock API client that can be used instead that returns some dummy data. Since we have both a real and mock implementations of each API client, we need to create an interface so that the endpoint doesn't need to worry about which it's actually using.
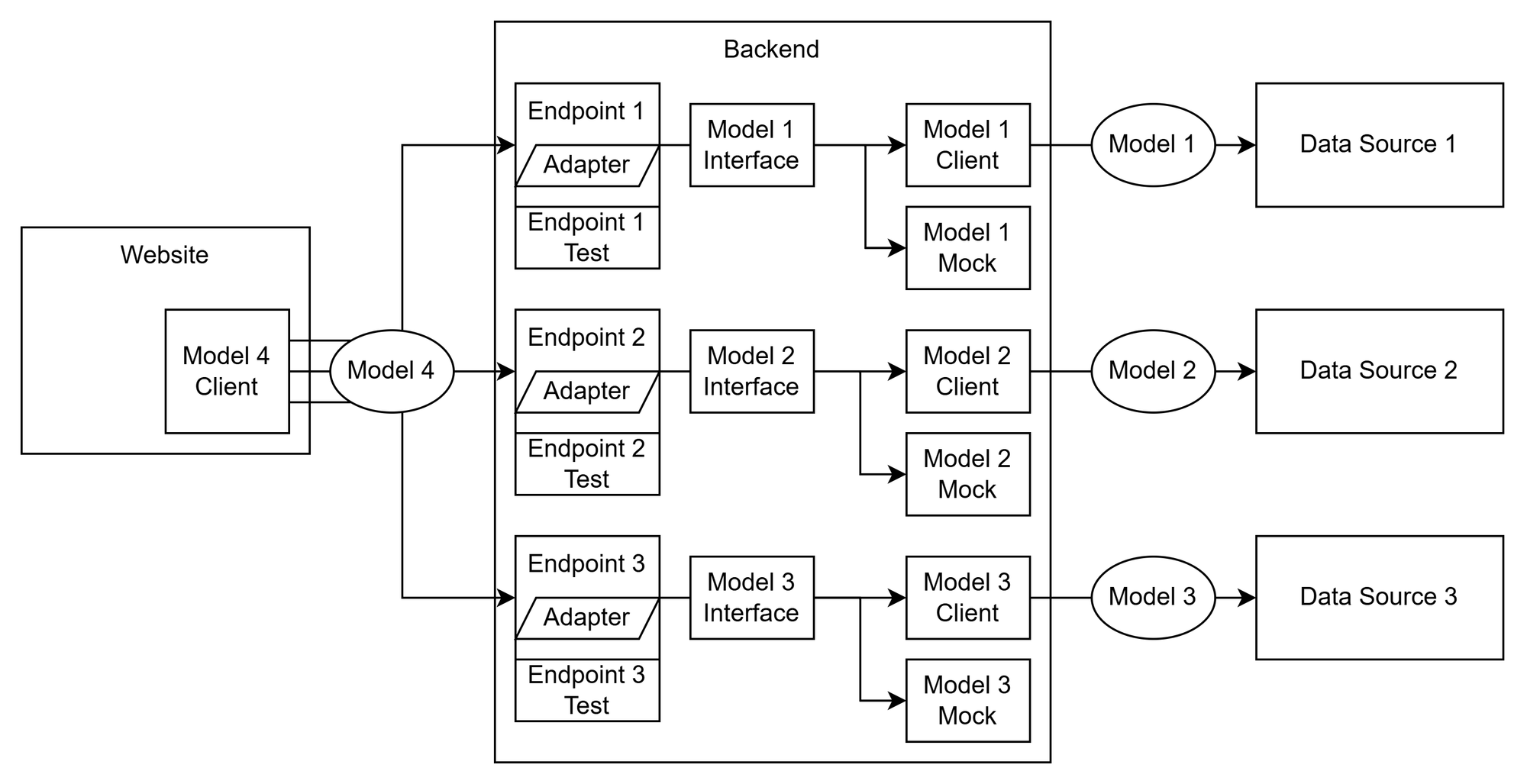
Ta-da! We finally have an enterprise grade piece of software. There are some other annoyingly confusing things I went through while working on this project, but this is more or less the codebase I was dropped into to add a few new endpoints. It would have been nice for me as a fresh new intern to have a diagram like this to explain the data flow, but alas, I had to figure this out by source diving. All things considered, I suppose it's not too bad.
But after editing 7+ files over 3 different repositories, I could finally implement a webpage that calls an API to display some data. At least it's good(?) code though!