Neuro Dev Log 1

Edit (5/6/2024): The GitHub repository is public here: kimjammer/Neuro, see what it's become now!
Today begins my journey to recreate Neuro sama until I get bored. I will try to record what I've learned each day in a dev log like this. Idk if this is something that deserves a dev log in the first place but whatever I guess lol. Also my "lessons learned" will contain anything I misunderstood, so don't assume this is correct information necessarily.
Today's goals were to understand the scope of the project and to learn what I will need to learn.
First I mapped out what kind of features and components would be required to recreate the core components of neuro sama. The core is really just a fast, local, tunable LLM, a realistic Text-to-Speech generator (with possibly a voice changer/cloner on top), and a fast Speech-to-Text transcriber. There's other things like integration with discord calls, image transcription, and integration with vtuber studio/live2d, but I'll deal with that later.
Now this sounded like a lot of different software that needed to be tied together, but as it turns out, many parts of this are already integrated in the very famous oobabooga/text-generation-webui project. This project lets you run an LLM of your choice locally, and it has extensions for TTS and STT so it kinda looked like this project was going to be easier that I first thought.
Then I started actually trying to run a model and realized there was a lot to learn. First, some background - my computer has 32gb of RAM and a 4070 w/ 12gb of VRAM. I had heard a lot about Mixtral 8x7B being very good recently, so when my search for a "good" local LLM wasn't all that fruitful, I tried running it, which failed. It didn't crash, so I'm not exactly sure what the problem was, but I later found out that my computer didn't really have enough memory for it.
Lesson 1: LLM memory requirement / Quantization.
A LLM (or any neural network really I think) has a certain number of parameters, or "neurons". To run an LLM, all of the parameters for every layer needs to be loaded into memory, so bigger the model, bigger the memory requirement. However, it turns out clever people figured out a technique called "Quantization" to "compress" these large models. In the model, parameters will have weights, which is a floating point number that determines how that parameter will behave. Normally these are 32 or 16 bit floating point numbers (as they usually are in most programming applications), but you can use less bits and just store the number less accurately. Since each weight for the parameters can be stored or "quantized" as 8, 4, or even just 2 bits, you can trade memory usage for quality. (I found this video very helpful in understanding what's actually going on: https://www.youtube.com/watch?v=mNE_d-C82lI) Companies/Organizations like Meta and Mistral publish their models at full precision, and community members (most notably TheBloke) pre-quantize these models to be 8 or 4 or whatever number of bits. So, normally, the Mixtral 8x7B model would require ~100gb of memory to run at full precision, but with 4 bit quantization, you could bring it down to ~27gb - which is of course still way too big for my 12gb 4070 so it absolutely filled up the VRAM and system RAM.
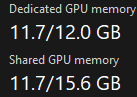
I think something weird might have happened here which prevented me from running the LLM. Anyway, I didn't realize that this model was 8 7B models combined, and not just 1 7B model, so this was kinda doomed from the beginning. After finding this very helpful list on some popular LLMs ranked (https://www.reddit.com/r/LocalLLaMA/comments/18u122l/llm_comparisontest_ranking_updated_with_10_new/), I chose to use the (older than Mixtral 8x7B) standard Mistral 7B-v0.2 instruct model quantized my TheBloke as it is here. I used the gptq-8bit-32g-actorder_True varient, which it an 8 bit quantized model that should have the best quality and require ~8.17gb of memory, which would easily fit on my VRAM.
Another thing I learned about is the different types(?) of quantization. There are different types, but what I gained from the previously linked youtube video is that GPTQ models are GPU optimized, GGUF models are better for running on the CPU, and AWQ models are also good for the GPU. They all achieve the same basic goal (compressing 32/16 bits down to 2/4/8 bits), but in slightly different ways with different priorities (Makes more sense when you learn how floating point number work). Anyway, seems like I will be sticking with GPTQ models from here forward, since they're needed(?) for LORAs I think. Not quite sure how those work yet either, but apparently you can fine tune how a LLM will output by training the model on some example data.
Misc
I also faffed about with Microsoft's Dev Drives where I trapped this project into a 50gb virtual dev drive. If I end up having to move all the files to a bigger one then whatever I guess.