Neuro Dev Log 2

Today's goals: Experiment with and get TTS and STT working.
So first I just installed the "builtin" coqui-TTS extension, and found that it worked, but not super well. I then found erew123/alltalk_TTS, which is a fork of the coqui-TTS extension with more features. The DeepSpeed option actually speeds up TTS a TON - would definitely recommend. I can get a good length output in 1-3 seconds. I tried cloning C's voice, from a previous audio clip I had of him, but it wasn't all that great. I tried cloning neuro-sama's voice from a youtube clip, but that went even worse I'm not sure how. Oh well. There's also the option to finetune the model itself, but I decided to leave trying finetuning for later.
For the STT, the built-in whisper_stt works well enough (especially with the base.en model), but I'm going to try to find a real-time transcription solution. Something like KoljaB/RealtimeSTT might work a lot better, since I could feed the finished transcription into the LLM as soon as the speaker is done talking. The ultimate goal is to reduce the latency from the moment the speaker stops talking to when the program starts outputting sound. Using the small.en took ~5 seconds to transcribe "my favorite food is a pizza", where as the base.en and tiny.en took ~2 seconds. That's not too bad, but if I can save another second by having the program transcribe as the person is still talking I'll take it.
I also tried faffing about with creating a LORA, which was not very successful. I pulled a copy of a discord channel I'm with a few friends using Tyrrrz/DiscordChatExporter, and isolated all of the messages from other C, and put it in a text file. I tried the default training settings then other stuff like 5 epochs, 1e-3 learning rate, etc but it didn't really seem to affect the model. It was a bit frustrating. I think I'll come back to it later maybe. I wasted a loooot of time on this.
I also tried adding an example conversation to the character/system prompt like they have an example for, but I don't think that this technique is really intended for the kind of style transfer I was looking for.
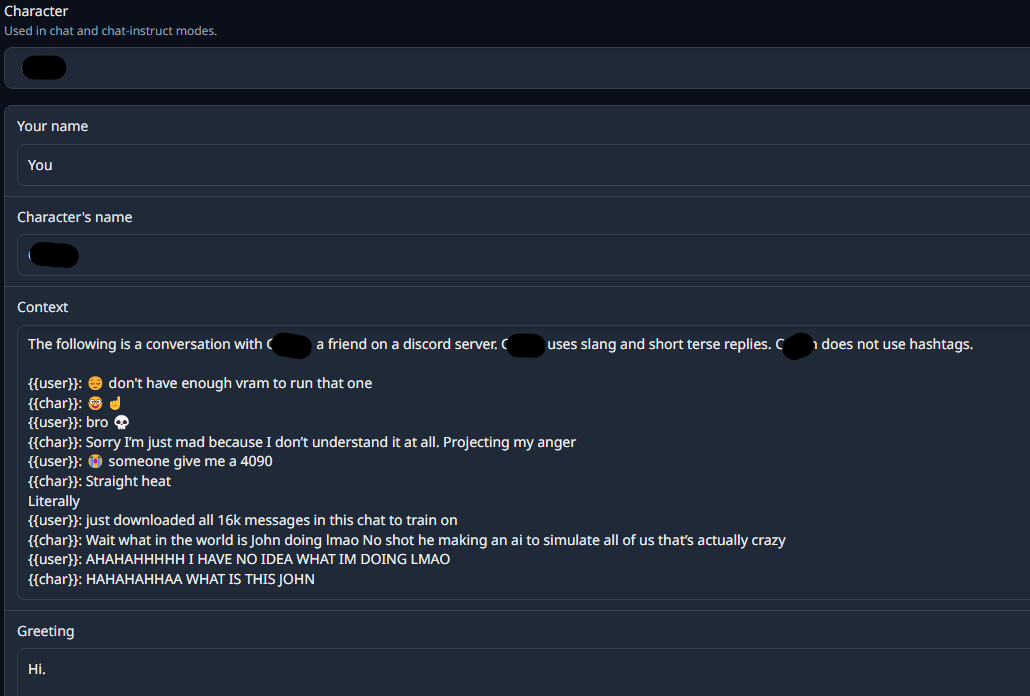
For whatever reason, this just made the AI spam #something all the time. Not sure why.
Regarding the LLM, I switched to the main Mistral-7B-Instruct-v0.2-GPTQ quantized model. This model is quantized to 4 bits, which leaves enough vram for the other AIs I'm going to need, and it also makes inferencing a lot faster.
I also found an amazing speedup for the LLM itself. Since yesterday, I was using the Transformer backend (since it just kinda seemed the most capable or whatever), but I discovered that switching to the exLlama (specifically ExLlamav2_HF) would make the LLM a lot faster. Before I was getting ~10 tokens/s at best, but now I can get up to ~50 tokens/s which is blazing fast. This means outputting a good length paragraph in just 1.66 seconds or a long sentence in under a second. Normally you only need ~8 tokens/s to match human reading speed, but I need the whole output asap so I can feed it into the TTS. This speedup is HUGE!

Lesson 1: You can speed up your LLM with lower quantization and the right backend.
Switching to a 4 bit quantized model from the 8 bit and switching to the exLlamav2 backend (accepts GPTQ) made the LLM run a loooot faster, putting real-time conversation within reach.