Neuro Dev Log 8

It has been a while since the last dev log, huh? I haven't been sleeping on the project though. Let's run through all the updates/changes.
First things first: A frontend/control panel.
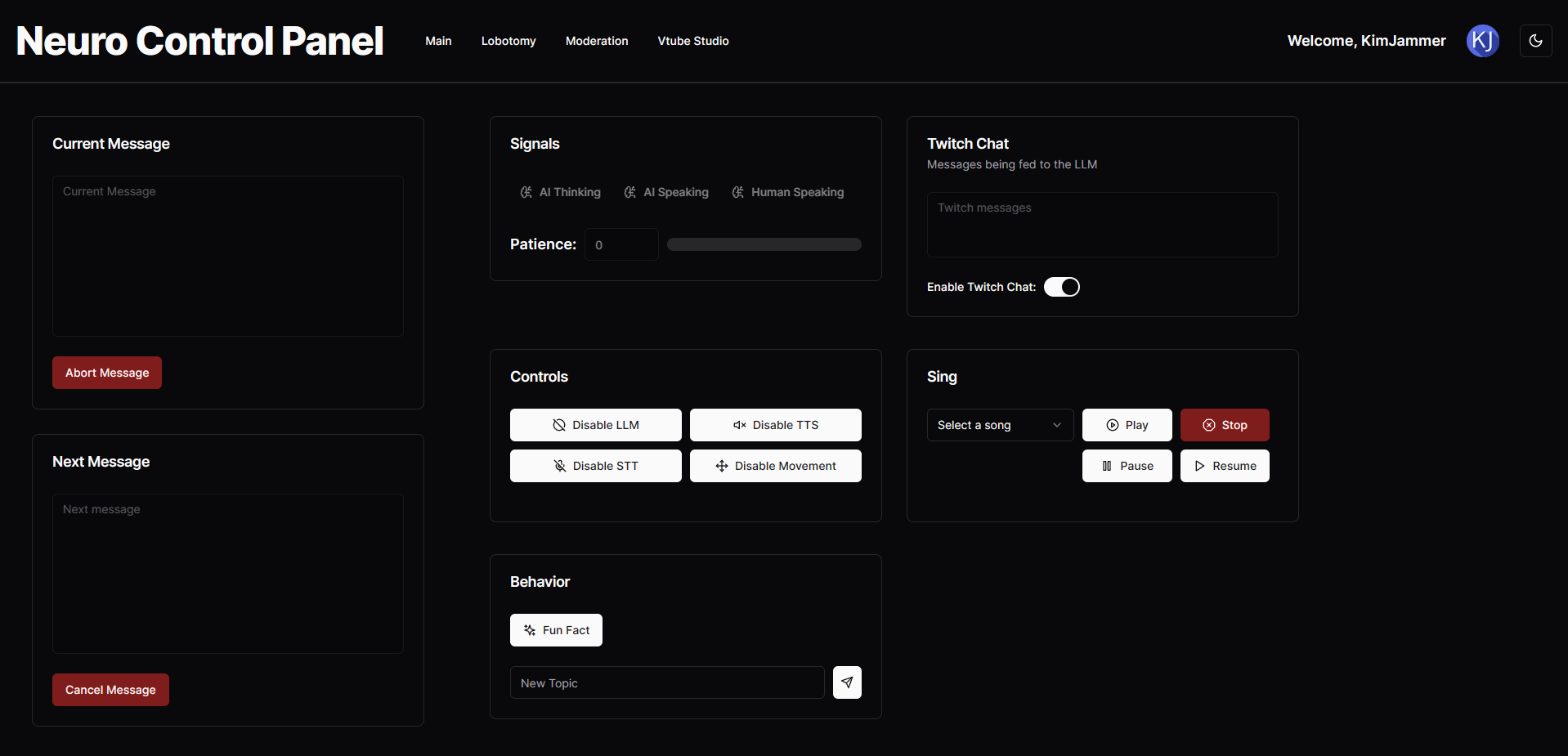
At first, this was just an excuse to install and learn Figma, since I've been wanting to do something like that for a while now. Soon, I found myself writing the code for it. I'm using my favorite frontend framework - Sveltekit, with the shadcn-ui svelte as the component library. This is also where I learned to use Tailwind CSS for the first time. I thought I would hate it, but when the details of the styling are handled by the component library and you only need to worry about the overall layout, Tailwind is surprisingly fluid! I was genuinely amazed at just how easy everything came together. Then I implemented a socket.io based communication protocol to ferry data to and from the frontend to the backend.
It was a bit of pain since my backend code was quite a mess with a mix of multithreading, event loops, and other badness. After a lot of head scratching and trying to figure out what the best method to untangle everything was, I managed to actually read up on what you're supposed to do and implemented queues for cross-thread communication. Everything fixed itself after that. For simplicity, almost everything now runs in its own python thread with its own event loop so I can use await and stuff.
Next up: Another backend refactor.
But for a good reason. I want/need this project to be somewhat easily extendable, since I'll be experimenting with a lot of different AI bits and bobs. So I refactored everything that wasn't a core part of the program (twitch bot, etc) into a "Module". A module is just a class that has a run() function, and can provide "Injections". Injections is how I decided to organize my actual LLM prompts. An "Injection" has some content text, and a numeric priority. When the LLM is being prompted, every injection will be sorted from lowest to highest, and concatenated together. Things that should be near the top of the context, like the system prompt, have a really low priority, and modules can provide injections with its own priority to dictate where they should go in the prompt. Modules are run in their own thread with its own event loop.
Can't forget: Proper Audio Solution
ReatimeTTS finally lets you select your output device without my monkeypatch! Yay! Now was a good time to actually figure out a comprehensive audio piping and management solution. And you know what, [Voicemeter Potato](https://vb-audio.com/Voicemeeter/potato.htm) is just the tool for the job - and its free too! Now I can pipe audio into and out of Neuro and likewise for Discord. So I hear everything that's happening on the computer, Neuro hears me and the discord call I'm in, and the stream output can receive everyone talking and the computer audio. It's perfect. I had to read the rather chunky manual, but once I did that everything made pretty good sense.
A new feature for once: Singing!
It's singing time! Since singing synthesis is difficult/impossible to do in real time right now, all singing synthesis must be done separately before the stream. This makes the actual singing portion of the neurobackend repository a glorified mp3 player, but I still think it works great.
Ok, here's the actual singing synthesis pipeline. I use [RVC-Project/Retrieval-based-Voice-Conversion-WebUI](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI). This project has a built-in method of splitting the vocals from a song, and it can use a model trained on speech to convert the song vocals to the target voice. I had already experimented with this in the past, and nothing better has seemingly come out in that time, which is why I used it. I then overlay the instrumental and the new vocals in audacity. Very simple and straightforward. So simple and straightforward actually, that I had cobbled together a discord bot for this last year. But I didn't use that because I had to essentially monkey patch my own API into it. That's it! The model is trained on some rather low quality data of Neuro-sama in a storytelling stream.
What's Next?
Well, with the very recent release of Llama 3, I've been updating the repo to work better with Llama 3. It's actually smart enough to not need the generation prompt ("Neuro: " after the end of instruction token), so I've refactored everything to only rely on the /chat/completions endpoint instead of the deprecated and model-dependent /completions endpoint. It's 8B, not 7B, so it's a bit heavier to run, but the quality is so much better than Mistral 7B instruct v0.2 that it's not a contest.
I've also been looking into ✨multimodal ✨AI models. Some are quite impressive, like [OpenGVLab/InternVL](https://github.com/OpenGVLab/InternVL) with the InternVL-Chat-V1.5 (with upto 4k(!) resolution) but are very big (26B). The runner up has been [Llava-1.6](https://github.com/haotian-liu/LLaVA), but there aren't any versions with Llama 3 as the base yet, so I'm kinda just waiting now. Also, support for multimodal llms are really spotty, with the best option seeming like a custom API from llama.cpp that they removed at some point. Which is really unfortunate because I think it would be awesome to give Neuro eyes and let her see content to react to or games that we're playing. But hopefully that changes soon.
There's a few other things on the todo list, like subtitles and some graphic design for the reaction stream format. But one high priority is to get some actually high quality voice data to clone. Right now its using a clip of Neuro-sama and with the background music and the TTS-nature of that clip, it's not a great reference clip to use. I don't know exactly how I'll ethically source a reference voice clip, but hopefully I figure something out. Because the XTTSV2 model is quite capable of rather good sounding voices, it just messes up so bad right now because of the low quality input.